Lecture version from Spring 2018
Webpage from https://www.cs.cmu.edu/afs/cs/academic/class/15418-s18/www/
resources:
Lectures
Lecture 1: Why Parallelism
More efficient pipelining 指令高效流水线(Instruction Efficient Pipelining)
ILP,指令级并行(Instruction-Level Parallelism)
Intel曾以频率作为性能代名词来营销,但2004年以来频率不再以指数级增长,被迫转而堆积核心;引出散热问题和对并行的要求
并行要关注:任务的平衡性
Speed != Efficiency
Lecture 2: A Modern Multi-Core Processor
refer:https://zhuanlan.zhihu.com/p/522901372
前Multi-Core 时代
ILP,指令级并行:如何理解?
分支预测-算法与设计:如何理解?
超标量与流水线技术?
out-of-order execution 乱序执行(Out-of-Order Execution)是一种现代计算机处理器的执行策略,旨在提高指令级别并行性(ILP)和执行效率。它的核心思想是在不影响程序的语义正确性的前提下,允许处理器在执行指令时不按照它们在程序中的顺序来执行,以便充分利用处理器的资源并提高指令执行速度。
多核时代
SIMD,即单指令多数据(Single Instruction, Multiple Data),是一种并行计算的计算机体系结构设计范例。其基本思想是,对于一些需要对相同类型和大小的多个数据元素执行相同操作的情况,可以使用一个指令来同时控制多个ALU,从而实现数据的并行处理。例如,如果要对两个长度为4的整数数组进行逐元素相加,可以使用一个SIMD指令来同时控制4个ALU,每个ALU负责一个元素的加法,这样就可以在一个时钟周期内完成4个元素的加法,而不是使用4个普通指令来分别执行每个元素的加法。
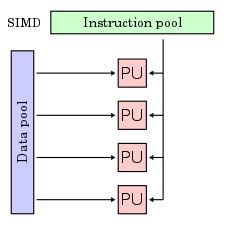
instruction stream coherence
SPMD (on GPU)
Superscalar?
Accessing Memory
Prefetch: Guess which memory the date in
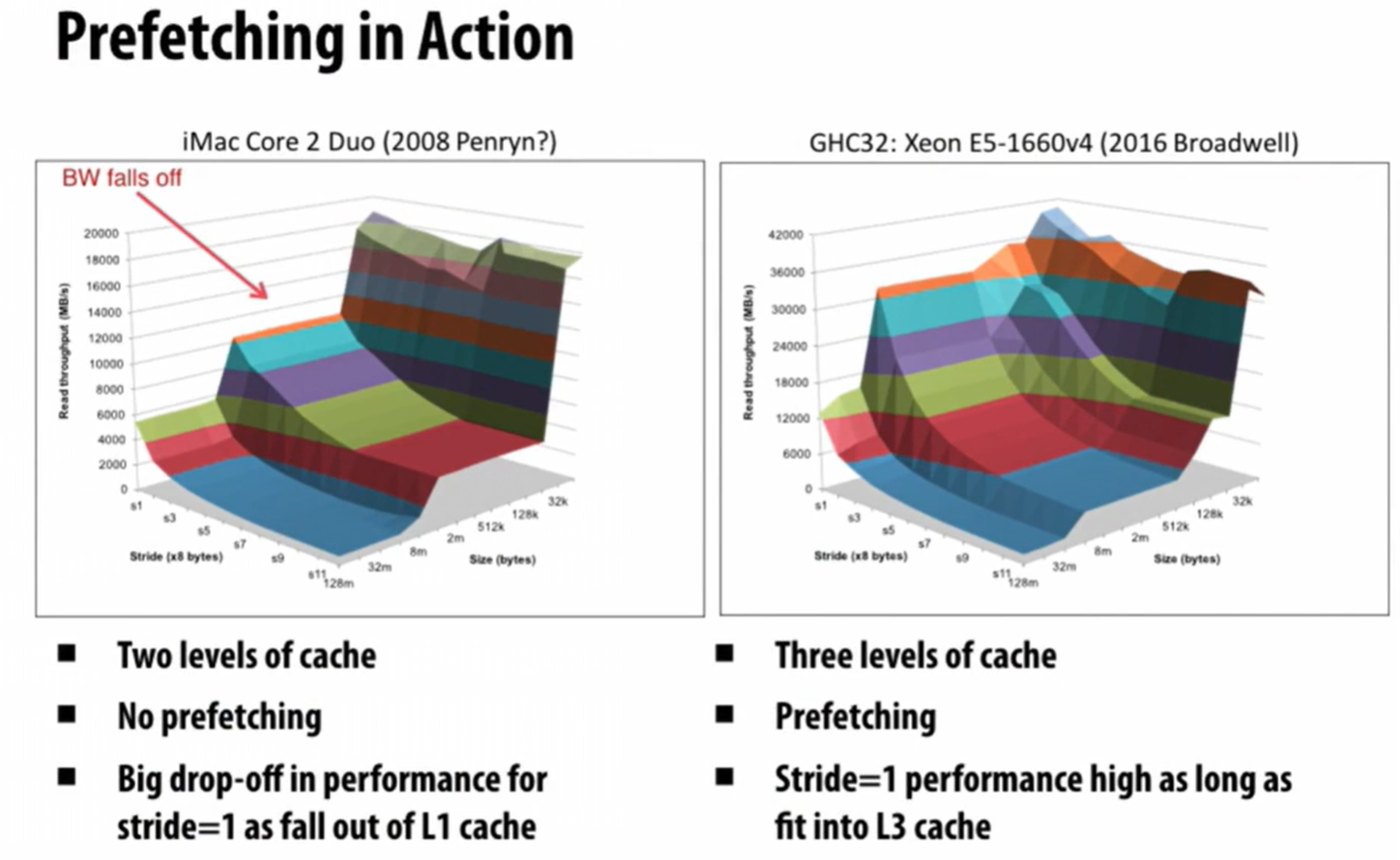
this technology is discussed in CSAPP p.446
Multi-threading
就是超线程的思想,对于访问同一块cache的进程,让最先准备cache的thread stall,直至所有thread都runnable再execute
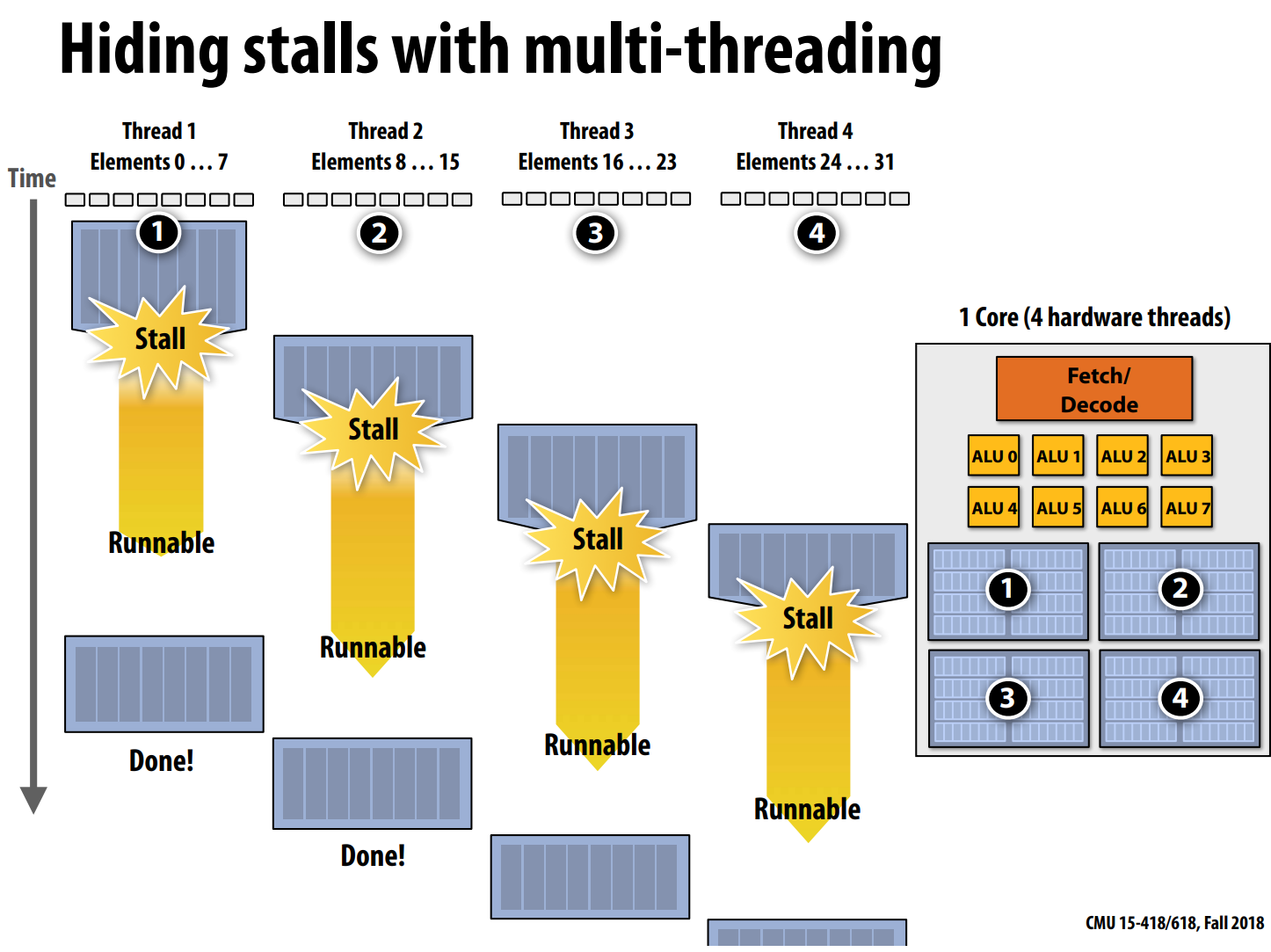
实际上降低了单一thread的速度(看Tread 1),来换取计算的吞吐量,throughout-oriented computing
是一种multiplexing复用的技术
Lecture 3: Parallel programming models
ISPC Intel SPMD Program Compiler
SPMD single program multiple data
.ispc file
interleaved assignment (much faster) / blocked assignment
foreach
Three kinds of abstraction
Stream and Kernel
Lecture 4: Parallel programming basics
目标:提升加速比。
- Amdahl’s Law is stated as:
$$ S(s)=\frac{1}{(1-p)+\frac{p}{s}} $$
意义:并行的最大加速比取决于程序中必须顺序执行的部分的耗时占比
- 那么如何编写一个并行计算程序?
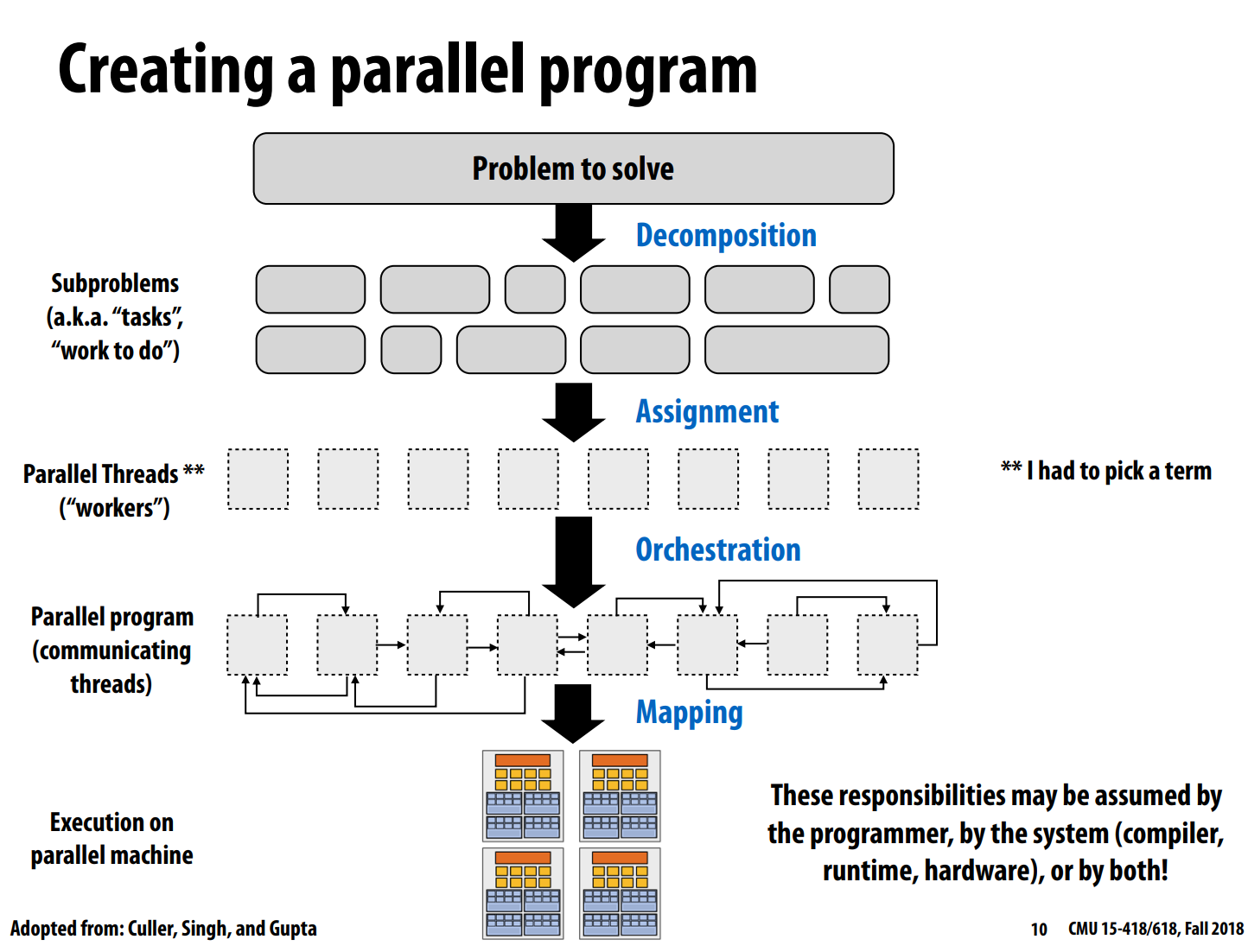
主要分为4个步骤:
- (decompostion)分解问题至多个子问题(tasks)
- 需要分析、研究问题中可以并行的地方
- 目标:创建足够多的tasks,可以让机器可以充分地忙碌。
- 分解的关键是识别程序中的依赖。因为根据阿姆达尔准则,程序的最大加速比取决于程序的依赖。例如,假设S为程序中必须顺序执行的部分耗时的占比,那么最大加速比小于1/s。
- 一般由程序员负责问题的分解。
- (assignment)将子问题(tasks)分配到并行的线程(workers)
- 需要考虑局部性,负载均衡等
- 目标:负载均衡,减少通信消耗
- 负载均衡,和减少通信消耗是很难同时做到的,例如负载均衡最好的方法是随机分配到各个worker,但这样会使得局部性变弱。
- 可以一开始分配完(静态分配, 如程序员使用pthread API将task分配),也可以边执行,边根据情况分配(动态分配,如ISPC中tasks到线程的分配)。
- 一般由程序员负责(如lecture2中讲ISPC时的前两个版本),有些语言或者runtimes也会负责(如ISPC中的
foreach,以及ISPC中tasks到线程的分配)
- (orchestration)协调多个workers的执行
- 需要结构化workers间的通信(如消息传递模型中消息的结构),添加同步, 组织数据在内存中的存储以减少时间消耗, 调度tasks等
- 目的:减少通信和同步的消耗,保留数据引用的局部性,减少overhead(除必要计算外的额外消耗,如通信)。
- 实现和细节依赖于使用的通信模型,编程抽象,如共享地址空间还是消息传递等。
- 硬件细节会影响该过程。例如,如果同步消耗很大的话,需要减少它的使用。
- (mapping)将workers分配到具体的硬件上执行。
- 需要考虑局部性,硬件特性等
- 相关线程放到一个处理器或者core可以更好地利用局部性,减少通信和同步的消耗
- 不相关的线程放到一个处理器或者core可以使得机器运行的更加高效,如一个是计算型线程,一个是IO型线程。
- 目的:将workers放置到具体的机器执行单元
- 操作系统,编译器,硬件,程序员都可以负责这个部分
- 操作系统负责:将线程分配到哪个core
- 编译器负责:将ISPC的程序实例映射到向量指令
- 硬件负责:将CUDA线程放置到GPU cores
- 程序员负责:设置线程对core的亲和性,可以使操作系统将线程分配到指定core。
- 需要考虑局部性,硬件特性等
当我们说一个问题的计算量很大时,该问题有三种类型,分别是计算型,数据型和混合型。旅行商问题就是计算型,它的数据就只有几十个坐标,但需要很大的计算量。
而计算几百亿个数的sin,则属于数据型,单个数的sin计算很快,计算量大是因为数据多。
而对几亿个数的排序,是混合型,数据和计算是混在一起的。
面对一个问题,我们可以尝试从计算和数据两个维度对问题进行分解。
- 本节重点之一是通过一个具体 Parallel Program 关注 如何识别依赖dependencies
Lecture 5: Work distribution and scheduling
Imbalance
Cilk
cilk_spawn
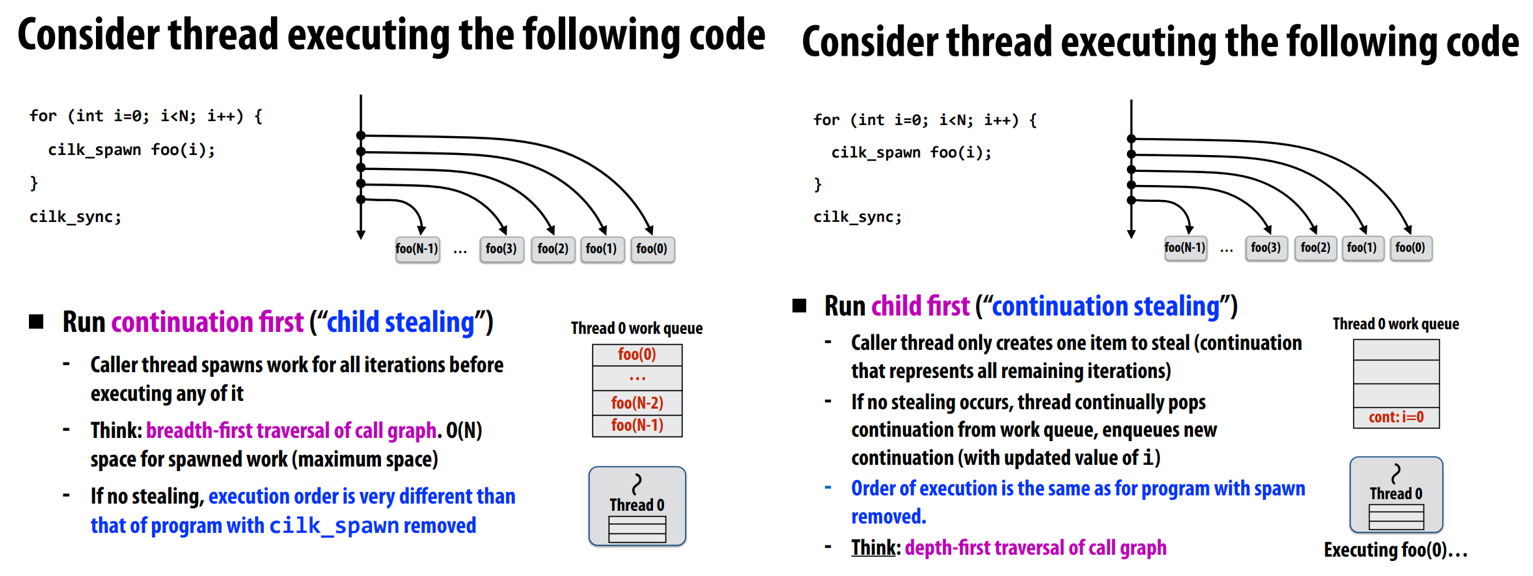
Run continuation first “child stealing”
- 在执行前先生成所有子任务,类似宽度优先遍历
Run child first “continuation stealing”
当主线程(例如Thread 0)启动一个任务时,它首先执行这个任务(称为“child”),并将循环的“continuation”(即接下来的迭代)放入其工作队列。
如果另一个线程(例如Thread 1)没有任务可执行,它可能会steal主线程的“continuation”,然后执行下一个迭代。
类似深度优先遍历
分治法 最好 steal from head (先做耗时长的任务)
一般意义上,random steal 可以避免极端imbalance
cilk_sync
greedy policy 贪心策略进行同步
Summary:

Lecture 6: Graphic processing units and CUDA
GPGPU General Purpose GPU
thread 的多重含义