Access for Lab-server
- ssh 02_thinksource@222.20.96.149 -p 10022 访问服务器
- 密码是:Ym2N7Q72E4
ssh -L 8888:localhost:8888 02_thinksource@222.20.96.149将jupyter notebook的端口映射到本地,然后复制notebook的链接至浏览器即可打开- 关闭notebook时需在终端两次
Ctrl+C - 退出ssh连接,在终端执行
exit
Models
MLP的隐藏层,若视为矩阵变换,可以当作对输入向量的升维操作,而在高维空间中,便可能找到一个超平面对输入进行划分(找到数据的划分是处理机器学习基本问题——分类或回归问题——的本质)
RNN
对于含有时序信息的输入,模型需要有处理变长向量(Input)的能力,而MLP仅能处理固定长度的输入,因此设计了循环神经网络
Simple RNN
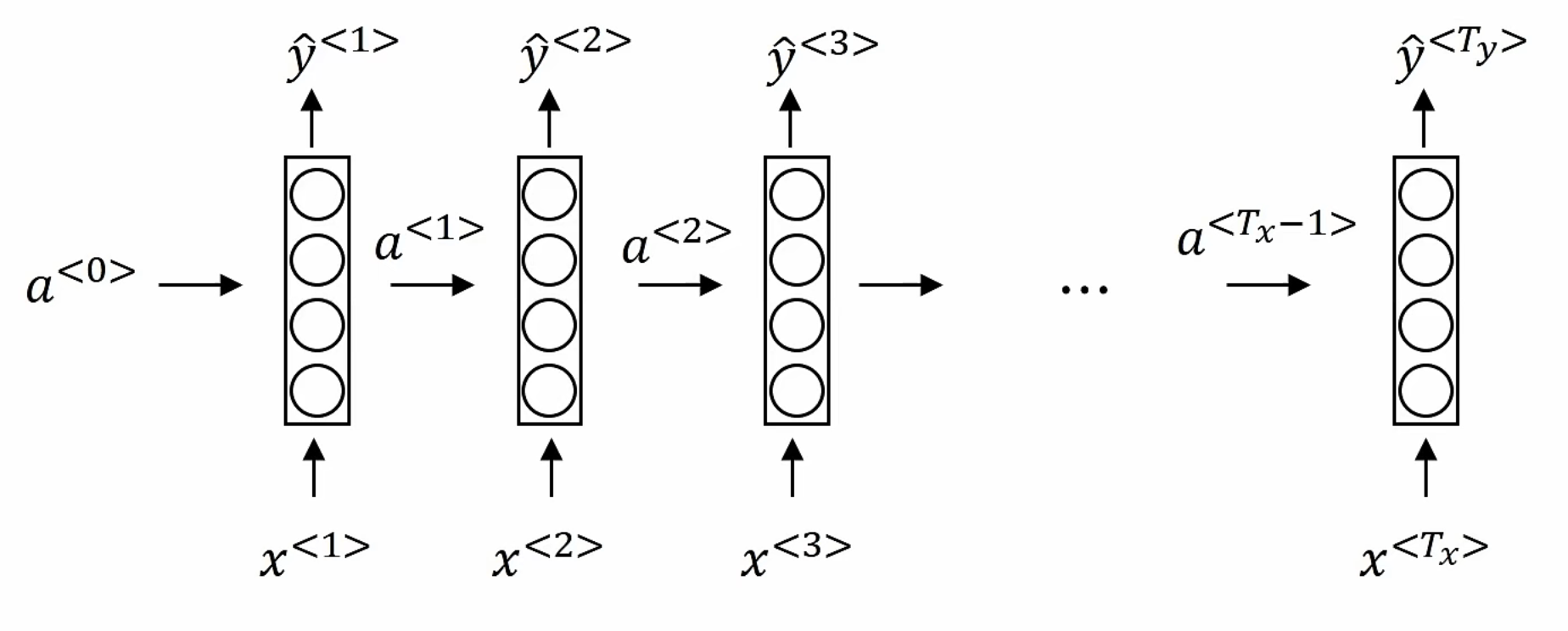
$a^{<0>}$通常初始化为全零向量,设置$a^{<0>}$是为了在网络开始时满足模型的循环结构
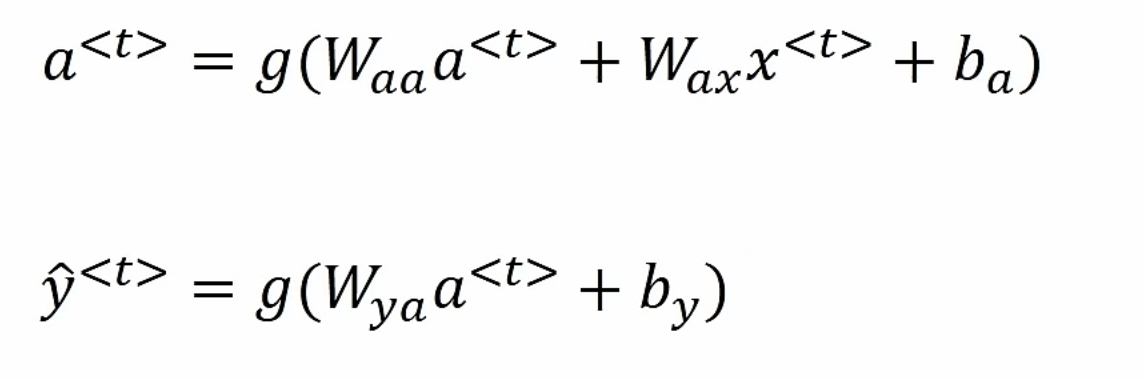
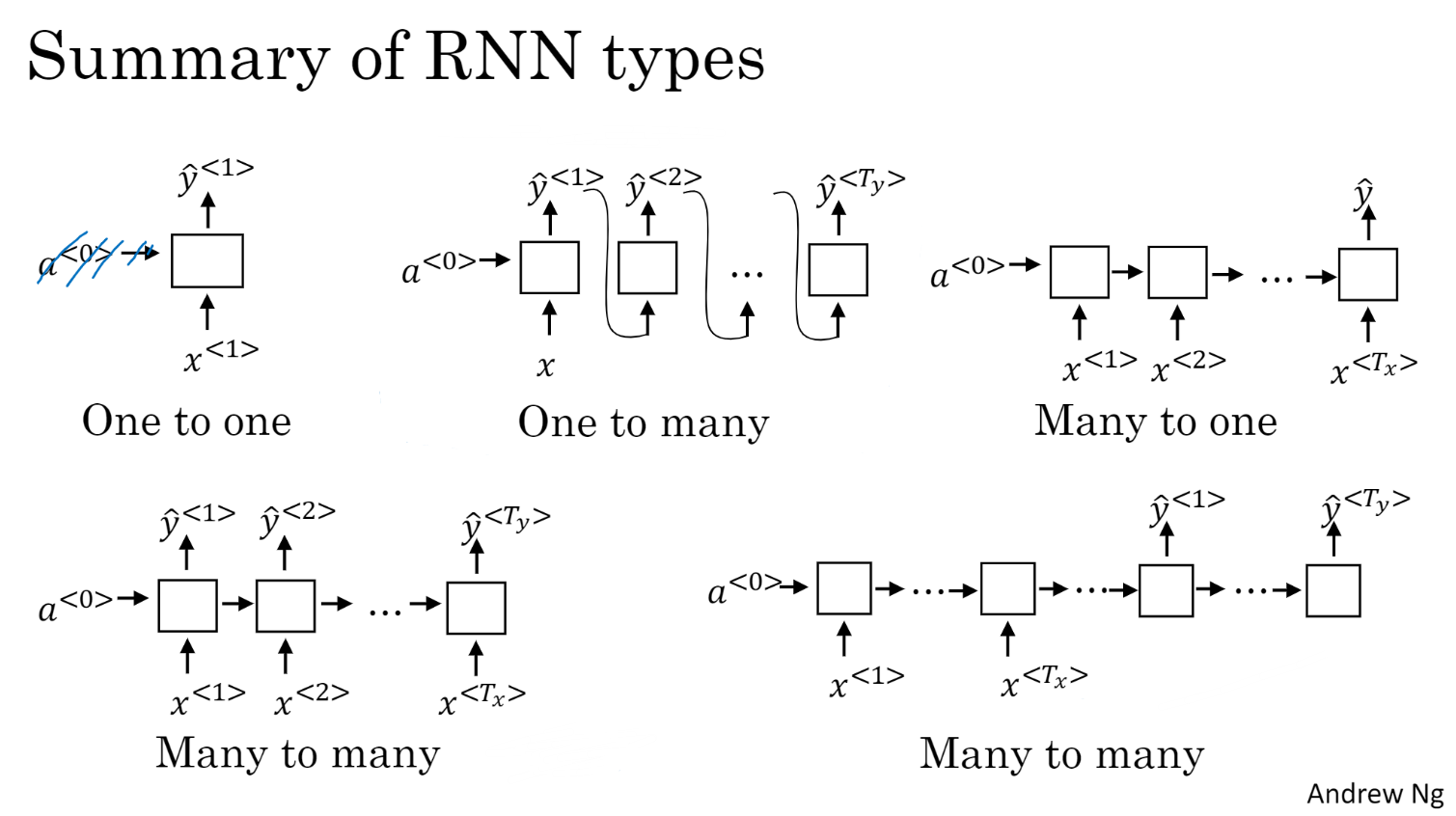
many to many问题中,更多是处理输入$x$和输出$y$长度不同的情形,因此设计了encoder-decoder模型
Vanishing gradients梯度消失:在多层的网络模型中,最后计算的梯度通过反向传播很难对靠前的层进行更改
梯度消失在RNN的现象即:当序列中具有长间隔的数据具有依赖性时(e.g. cats…..were/cat….was),网络很难“记住”
RNN训练时也会出现梯度爆炸(较罕见),表现为参数中出现NaN,可使用gradient clipping
GRU
- GRU有效避免了梯度消失
LSTM
双向RNN
深度RNN
Attention
- 注意力机制
- query value key
Transformer
self-attention
- 位置编码
multi-attention
batch norm和layer norm
Transformer 是一个纯使用attention的encoder-decoder
- encoder和decoder都有n个transformer块
- 每个块里使用multi(self)attention, Positionwise FFN, layer norm
BERT
- NLP问题上的预训练架构
Optimization
- 小批量随机梯度下降算法
- 梯度下降->随机梯度下降->小批量
- 冲量法
- Adam:效果不一定优于SGD,优点是对LR不敏感,不必过多调参
Neural Rendering
- Definition
- Deep neural networks for image or video generation that enable explict or implict control of scene properties