论文阅读顺序:
- 标题+作者
- 摘要
- 结论
- 导言
- 相关工作
- 模型
- 实验
- 评论
Multi-headed Attention: 为了模拟CNN可以达到多通道输出
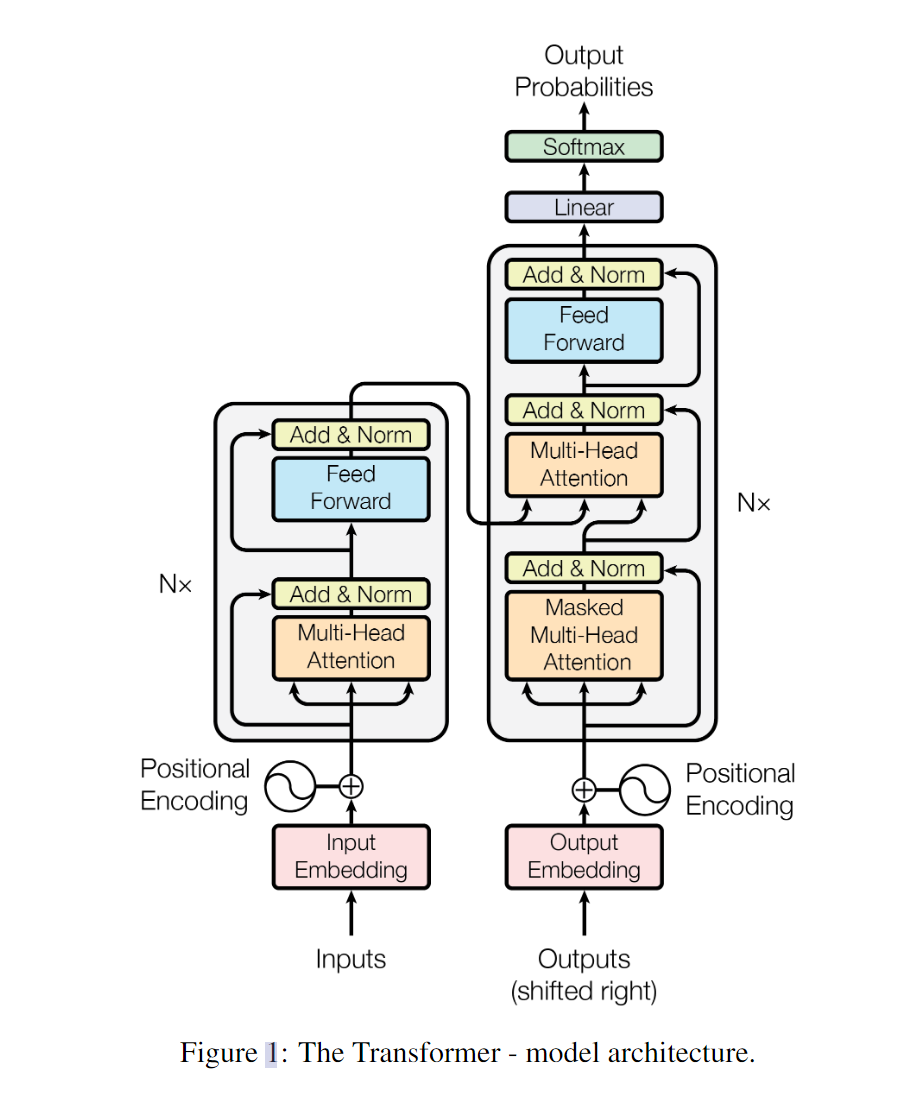
Model Architecture
自回归模型
:(对于decoder)过去时刻的输出也会作为当前时刻的输入
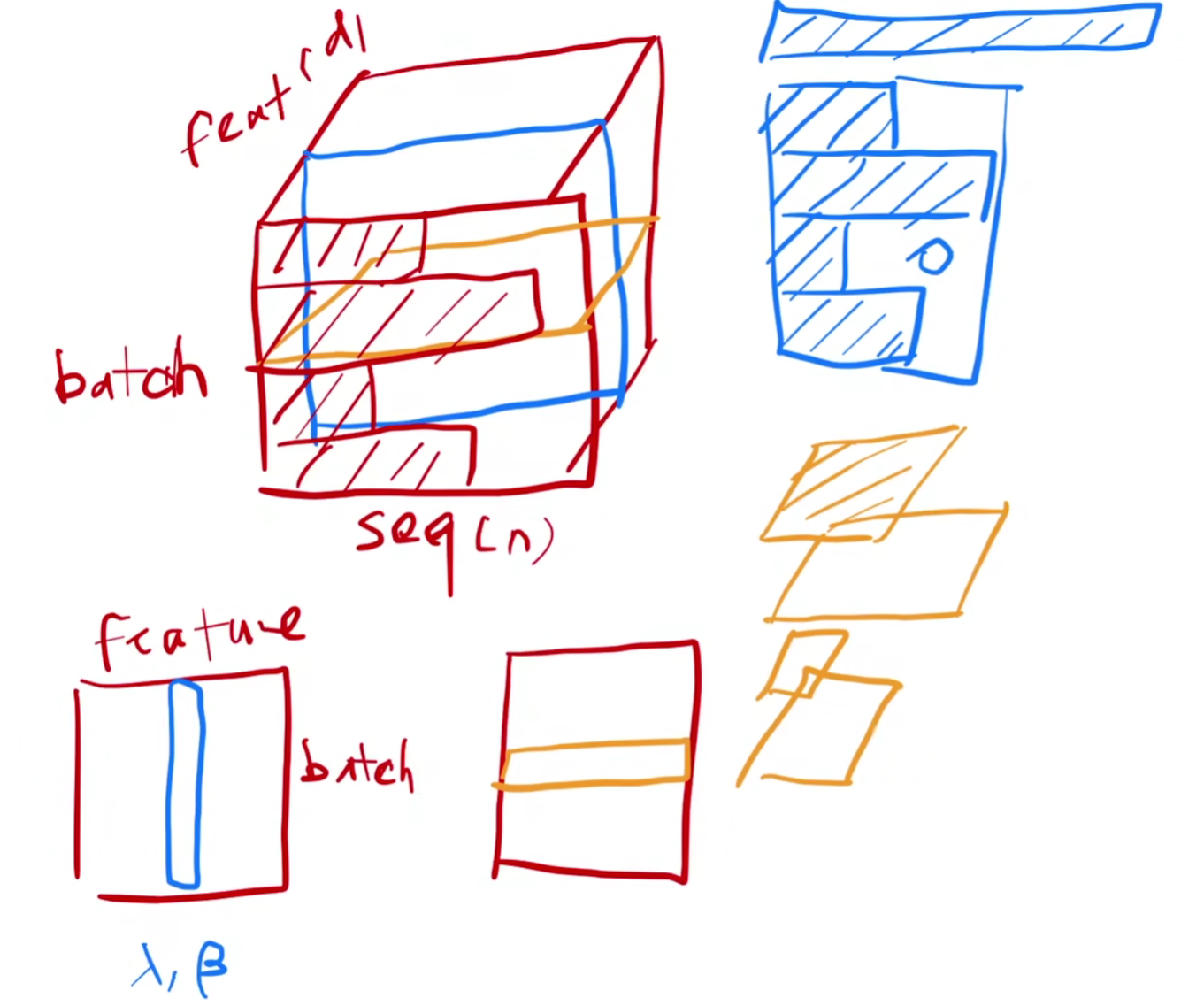
LayerNorm vs. BatchNorm
Batch: What is Batch? 一捆Data,以便处理时并行
Normalization: 均值化0,方差化1
BatchNorm就是对每个Batch(包含了不同的样本)做Normalization
LayerNorm就是对每个样本(包含了样本的特征feature)做Normalization
Attention & Multi-Head 计算图:
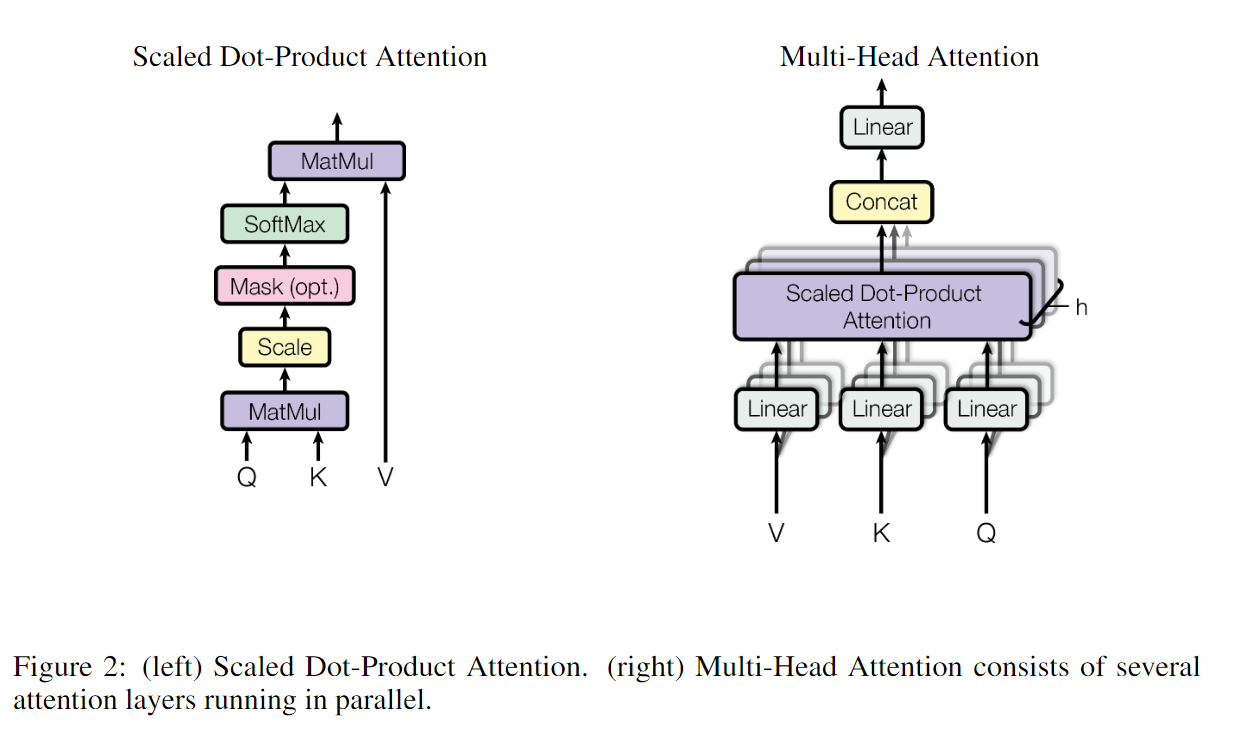
关注Attention算法:Key-Value pair 的作用,与Query对权重的影响
FFN: = MLP
Positional Encoding: 处理使Attention能获取时序信息
实验:
Dropout: 大量使用,做正则化,Dropout的意义?
评论:
Transformer在大数据集上还未出现数据饱和,也即,没有出现过拟合等现象